少有人走的路
少有人走的路1.把原始图像放到images目录;把类名写到classes.txt中,每个类名占一行;使用标注工具标注数据,标签图像将保存到labels目录;
(只要写defect类,背景不用写) (classes.txt里是类名)
2.运行2_train.hdev读入标注数据,训练得到网络;(epoch为500次,batchsize=1,learningrate)
3.运行3_infer.hdev使用训练好的网络推断新的图像;
目录说明:
images目录放原始图像
labels目录放标注数据
test 目录放测试图像
images文件夹内图片需要全部标注,标签会生成在labels文件夹。
关于语义分割标注流程:
打开1_labeltool.hdev,点击运行: 键盘方向左右切换图片 a:添加新的标注 n:为当前图片添加新的标签,并鼠标点击绘制,右键结束绘制 d: 保存当前标注结果 然后开始标注下一张 全部标注完后,按d,保存所有图片的标注数据集结果,并结束程序。
注:1.在标注程序统计目录下得到dataset.hdict文件
2.labels里得到图片文件名对应的标注图
(二者缺一不可)
下图是第一步使用标注工具标注数据
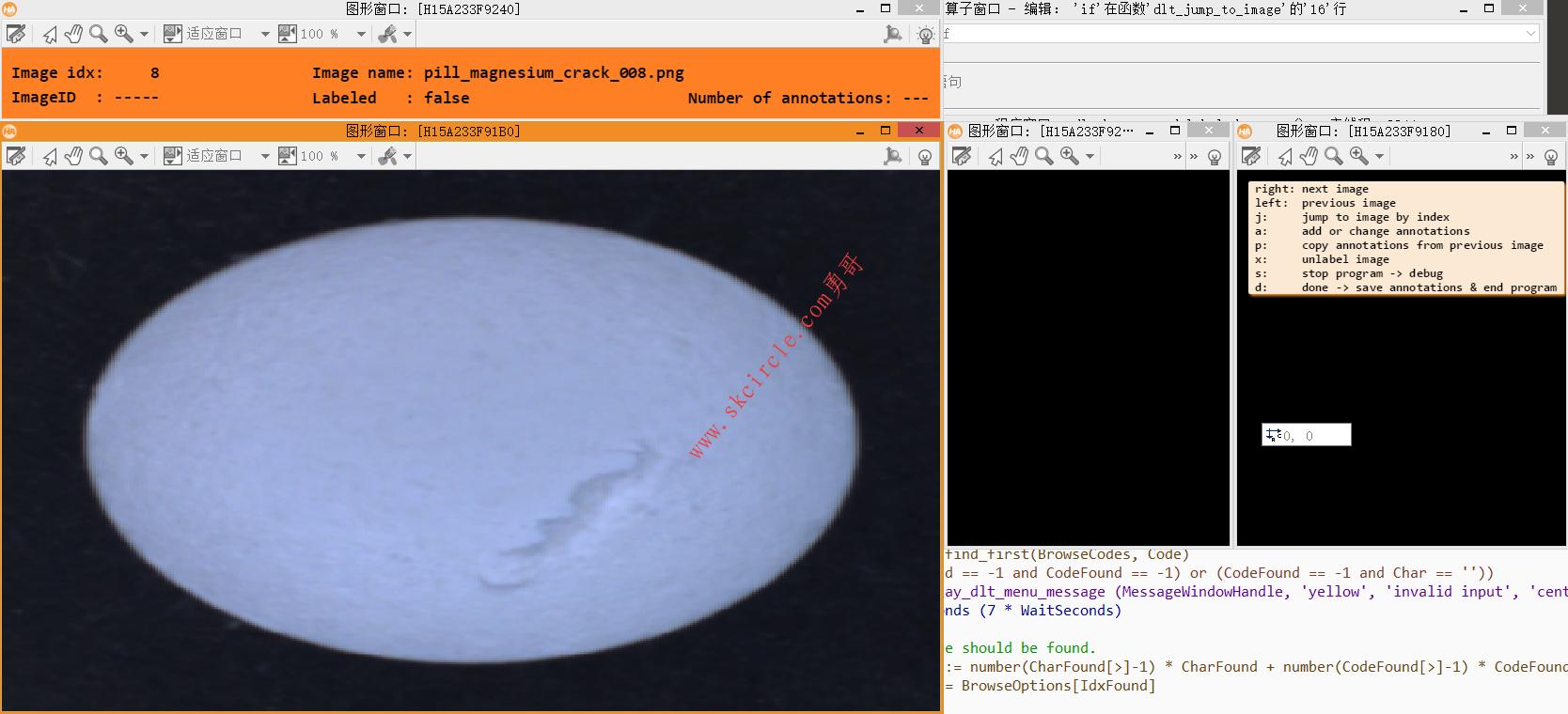
打开运行2_train.hdev读入标注数据,训练得到网络
下图是第二步,读入标注数据进行训练。
这个过程是相当漫长,训练图片几十张,才几M,居然要一个多小时。
训练:
train_dl_model (DLDataset, DLModelHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos)
其中DLDataset为上一步标注图像时生成的dataset.dict文件。读入在:
read_dl_dataset_segmentation ('images', 'labels', ClassNames, ClassIDs,
[], [], [], DLDataset)
//用于读取常用的注释数据
//第一个参数为原图路径,第二个参数是标注图路径,
//第三个参数是前面从class.txt中读取的目标类别名字
第四个参数是图片列表
dlt_read_classnames ('classes.txt', ClassNames) //从classes.txt中读取类别名(可自行在此txt文
件中修改)
ClassNames := ['background', ClassNames] //背景类和目标类样本集划分:
split_dl_dataset (DLDataset, 70, 15, []) //第一个参数是上一步生成的数据文件 第二个参数是训练子集的百分比 第三个参数是验证集的百分比 (剩下的即为test集的百分比) 第四个参数是一个字典,用于覆盖警告和更改模型默认值的,可以不用管,写[]就好了 这个函数作用是:将样本分成训练、验证和测试子集 每个子集中的样本数由给定百分比TrainingPercent和ValidationPercent定义。 因此,每个图片对应的sample都有一个key,为“split”,其值为“train”、“validation”或“test”。
create_dict (PreprocessSettings) //创建字典对象,设置
set_dict_tuple (PreprocessSettings, 'overwrite_files', true)
//在字典中存储与键关联的元组。字典由第一个参数表示。
//包含字符串的元组由操作复制,因此可以立即复用。空元组被视为可以与键关联的有效值。如果任何数据(元组或对
//象)已与给定的键(键)关联,则旧数据将被set dict元组销毁并替换为元组。
//第二个参数是key。
//第三个参数是一个tuple。
list_files('images', 'files', Files) //Files是训练原图路径列表
read_image (Image, Files[0])//读取第一张图片
get_image_size(Image, Width, Height) //获取图片的宽和高
Scale := 1
Width := (Width / Scale) //设置预处理参数
Height := (Height / Scale)
count_channels(Image, Channels) //获取图像的通道数
create_dl_preprocess_param ('segmentation', Width, Height, Channels,
-127, 128, 'false', 'full_domain', [], [], [], [], DLPreprocessParam)
//预处理参数
preprocess_dl_dataset (DLDataset, 'data', DLPreprocessParam, PreprocessSettings, DLDatasetFileName) //开始预处理
预处理:这一步预处理,执行完此函数,会在同级目录下生成文件夹data,里面的sample文件夹是转换格式后的图片文件;dl_dataset.hdict文件包含图片的文件名和ID等信息
preprocess_dl_dataset (DLDataset, 'data', DLPreprocessParam, PreprocessSettings, DLDatasetFileName) //这一步预处理,执行完这一步,会在同级目录下生成文件夹data,里面的sample文件夹是转换格式后的图片文件, //dl_dataset.hdict文件包含图片的文件名和ID等信息
参数设置:
//HALCON自带的两个预训练的语义分割模型,可以在目录dl中找到 Model := 'pretrained_dl_segmentation_compact.hdl' //预训练的模型文件:compact小型版 *Model := 'pretrained_dl_segmentation_enhanced.hdl' //enhanced加强版模型 *Model := 'model_best.hdl' //这是训练结束后生成的模型文件。对应loss最低的epoch对应的模型 NumEpochs := 500 // 训练的epoch次数 LearningRate := 0.0001*10 //学习率 Momentum := 0.99*0.99 //学习率动量更新参数 WeightPrior := 0.0005*0.0 // 0
classesID为[0,1]
create_dict (WindowDict) //创建字典对象
get_dict_tuple (DLDataset, 'samples', DatasetSamples)
//把转换格式后的图像文件加载到DatasetSamples列表(tuple)中
find_dl_samples (DatasetSamples, 'split', 'train', 'match', TrainSampleIndices)
//根据样本子集的格式检索KeyName与KeyValue匹配的样本的索引
*dev_set_draw ('margin')
for Index := 0 to |TrainSampleIndices| - 1 by 1
SampleIndex := TrainSampleIndices[round(rand(1) * (|TrainSampleIndices| - 1))]
read_dl_samples (DLDataset, SampleIndex, DLSample)
dev_display_dl_data (DLSample, [], DLDataset, ['segmentation_image_ground_truth','segmentation_weight_map'], [], WindowDict)
endfor
//循环:根据Halcon可视化设置里的设置的颜色染色可视化展示标注的图片。设置训练的参数:
read_dl_model (Model, DLModelHandle)//读取模型到DLModelHandle句柄中 set_dl_model_param (DLModelHandle, 'image_dimensions', [Width, Height, Channels]) //设置模型参数之图像维度,[宽,高,通道数],(这三个值在前面由原图获取) set_dl_model_param_based_on_preprocessing (DLModelHandle, DLPreprocessParam, ClassIDs) //图像预处理部分 tuple_min2(round(|DatasetSamples|*0.7), 64, BatchSize)/////设置Batchsize的地方 //调试后,这里Batchsize从这里得到的,计算出为35 //Datasamples为50个元素(全部样本集)的列表,取绝对值表示列表大小 //0.7是前面设置的训练集的比例 //所以这个函数是将前两个较小的值赋值给Batsize //那么更改Batcsize的时候应该可以注释掉这一行,换为(例如)BatctSize := 1 //这里的batchsize设置是按照之前划分的比例来的,batchsize设置为了划分的整个train子集的数量 set_dl_model_param_max_gpu_batch_size (DLModelHandle, BatchSize) //设置gpu训练的batchsize ,Batchsize这里显示的值是35 set_dl_model_param (DLModelHandle, 'learning_rate', LearningRate)//学习率 set_dl_model_param (DLModelHandle, 'momentum', Momentum)//学习率优化的动量参数 set_dl_model_param (DLModelHandle, 'weight_prior', WeightPrior)// 0 set_dl_model_param (DLModelHandle, 'runtime_init', 'immediately') create_dl_train_param (DLModelHandle, NumEpochs, 1, 'true', 42, [], [], TrainParam)///////////////////////// //此函数创建字典对象TrainParam(训练的参数和训练可视化的参数) //第一个参数:第一个参数为前面读取的模型,可在Model处修改 //第二个参数为训练的epoch次数 //第三个参数:定义下一个模型评估将通过多少个epoch,以便使用evaluate_dl_model确定最佳模型。 //第四个参数:定义是否显示训练进度(“true”)或不显示(“false”) //第五个参数42是设置用于随机数生成的种子 //第六七个参数不用管,更改默认值的 //第八个参数是此函数最后得到的TrainParam
开始训练:
//train函数 train_dl_model (DLDataset, DLModelHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos) //第一个参数:包含数据信息的字典DLDataset //第二个参数:模型句柄DLModelHandle,可在开头Model更改预训练模型 //第三个参数:包含训练参数和训练时可视化参数的字典 'TrainParam' //第四个参数:从第几个epoch开始训练 得到的结果: //第五个参数:一个字典元组,包含每个batch训练的输出。 //第六个参数:一个字典元组,返回在训练期间计算的汇总状态信息。
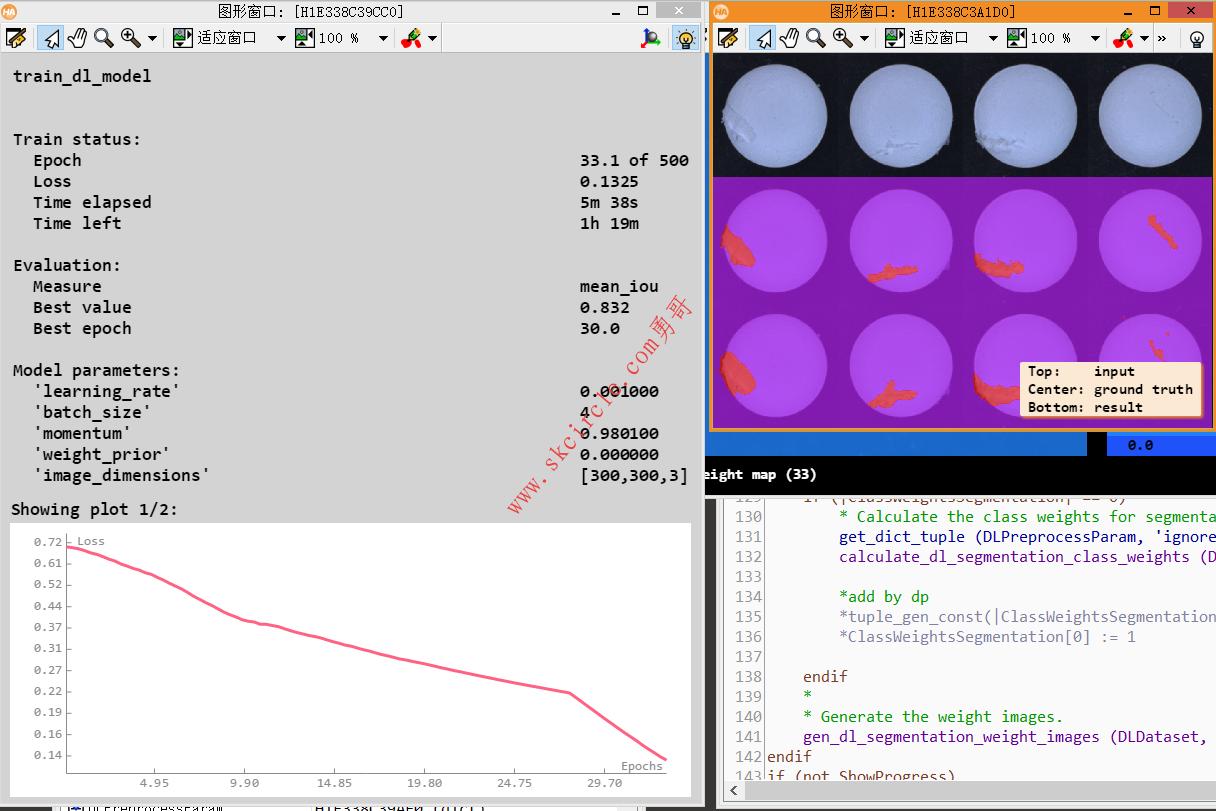
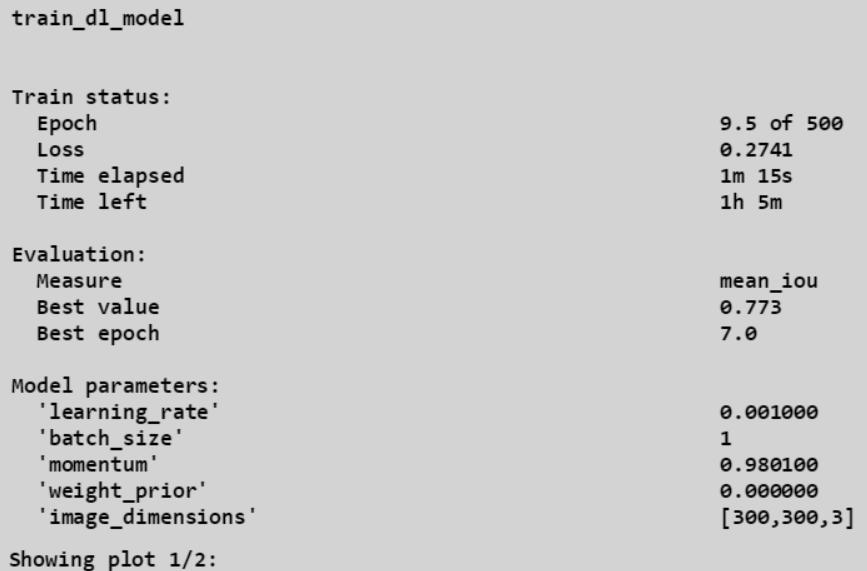
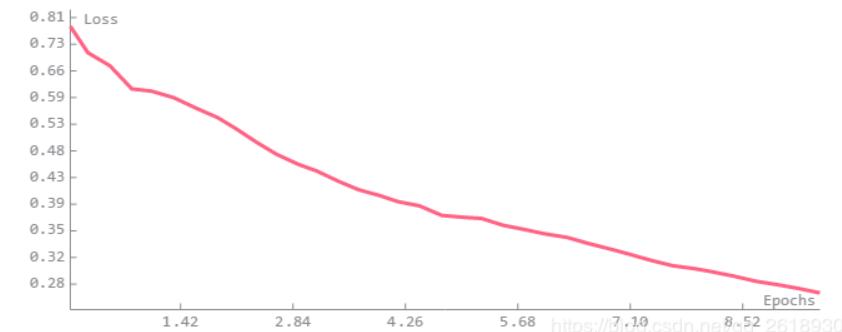
开始执行train_dl_model后, loss和miou等评估的一些指标都会可视化出来:
下方的图表展示loss和m-iou的变化情况:
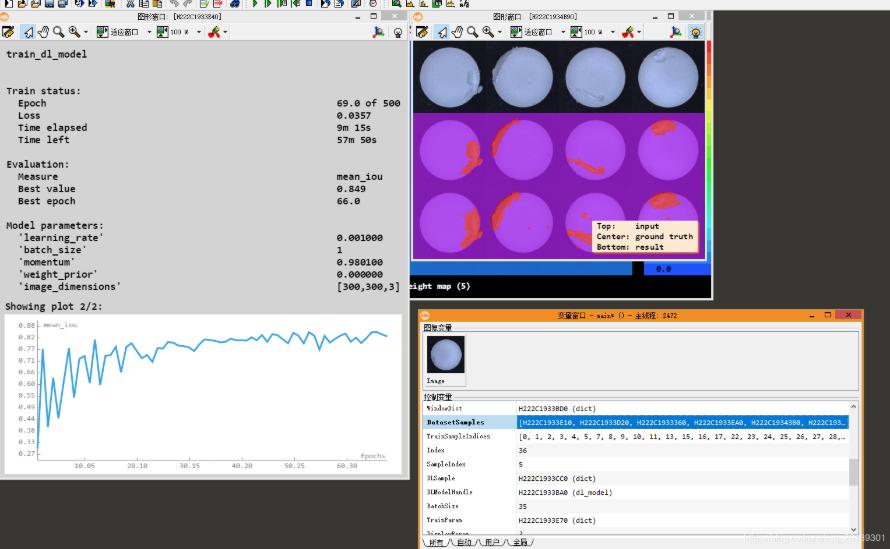
展示训练的状态:
当前模型的可视化结果动态更新:

完整源码如下:
Model := 'pretrained_dl_segmentation_compact.hdl'
*Model := 'pretrained_dl_segmentation_enhanced.hdl'
*Model := 'model_best.hdl'
NumEpochs := 500
LearningRate := 0.0001*10
Momentum := 0.99*0.99
WeightPrior := 0.0005*0.0
dev_update_off ()
dev_close_window ()
dlt_read_classnames ('classes.txt', ClassNames)
ClassNames := ['background', ClassNames]
tuple_gen_sequence (0, |ClassNames|-1, 1, ClassIDs)
*1.) prepare the DLDataset
read_dl_dataset_segmentation ('images', 'labels', ClassNames, ClassIDs, [], [], [], DLDataset)
split_dl_dataset (DLDataset, 70, 15, [])
create_dict (PreprocessSettings)
set_dict_tuple (PreprocessSettings, 'overwrite_files', true)
list_files('images', 'files', Files)
read_image (Image, Files[0])
get_image_size(Image, Width, Height)
Scale := 1
Width := (Width / Scale)
Height := (Height / Scale)
count_channels(Image, Channels)
create_dl_preprocess_param ('segmentation', Width, Height, Channels, -127, 128, 'false', 'full_domain', [], [], [], [], DLPreprocessParam)
preprocess_dl_dataset (DLDataset, 'data', DLPreprocessParam, PreprocessSettings, DLDatasetFileName)
* Inspect several randomly selected preprocessed DLSamples visually.
create_dict (WindowDict)
get_dict_tuple (DLDataset, 'samples', DatasetSamples)
find_dl_samples (DatasetSamples, 'split', 'train', 'match', TrainSampleIndices)
*dev_set_draw ('margin')
for Index := 0 to |TrainSampleIndices| - 1 by 1
SampleIndex := TrainSampleIndices[round(rand(1) * (|TrainSampleIndices| - 1))]
read_dl_samples (DLDataset, SampleIndex, DLSample)
dev_display_dl_data (DLSample, [], DLDataset, ['segmentation_image_ground_truth','segmentation_weight_map'], [], WindowDict)
endfor
*2.) TRAIN
read_dl_model (Model, DLModelHandle)
set_dl_model_param (DLModelHandle, 'image_dimensions', [Width, Height, Channels])
set_dl_model_param_based_on_preprocessing (DLModelHandle, DLPreprocessParam, ClassIDs)
tuple_min2(round(|DatasetSamples|*0.7), 64, BatchSize)
set_dl_model_param_max_gpu_batch_size (DLModelHandle, BatchSize)
set_dl_model_param (DLModelHandle, 'learning_rate', LearningRate)
set_dl_model_param (DLModelHandle, 'momentum', Momentum)
set_dl_model_param (DLModelHandle, 'weight_prior', WeightPrior)
set_dl_model_param (DLModelHandle, 'runtime_init', 'immediately')
create_dl_train_param (DLModelHandle, NumEpochs, 1, 'true', 42, [], [], TrainParam)
*验证样本数量太少不足以支持一行四列显示
if (|DatasetSamples| < 20)
get_dict_tuple(TrainParam, 'display_param', DisplayParam)
set_dict_tuple(DisplayParam, 'num_images', 1)
set_dict_tuple(TrainParam, 'display_param', DisplayParam)
endif
train_dl_model (DLDataset, DLModelHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos)
dev_close_window ()
dev_get_window(WindowHandle)
dump_window(WindowHandle, 'png', 'train')
*3.) EVALUATE
*clear_dl_model (DLModelHandle)
read_dl_model ('model_best.hdl', DLModelHandle)
create_dict (GenParamEval)
set_dict_tuple (GenParamEval, 'show_progress', true)
set_dict_tuple (GenParamEval, 'measures', ['mean_iou','pixel_accuracy','class_pixel_accuracy','pixel_confusion_matrix'])
evaluate_dl_model (DLDataset, DLModelHandle, 'split', 'test', GenParamEval, EvaluationResult, EvalParams)
create_dict (GenParamEvalDisplay)
set_dict_tuple (GenParamEvalDisplay, 'display_mode', ['measures','absolute_confusion_matrix'])
dev_display_segmentation_evaluation (EvaluationResult, EvalParams, GenParamEvalDisplay, WindowDict)
dev_get_window(WindowHandle)
dump_window(WindowHandle, 'png', 'matrix1')
dev_close_window ()
dev_get_window(WindowHandle)
dump_window(WindowHandle, 'png', 'matrix2')
*** Inference.
* Display some results on test images.
set_dl_model_param (DLModelHandle, 'batch_size', 1)
create_dict (WindowDict)
get_dict_tuple (DLDataset, 'samples', Samples)
find_dl_samples (Samples, 'split', ['test'], 'or', SampleIndices)
for Idx := 0 to |SampleIndices|-1 by 1
read_dl_samples (DLDataset, SampleIndices[Idx], DLSample)
apply_dl_model (DLModelHandle, DLSample, [], DLResult)
dev_display_dl_data (DLSample, DLResult, DLDataset, ['image', 'segmentation_image_ground_truth', 'segmentation_image_result'], [], WindowDict)
stop ()
endfor
dev_display_dl_data_close_windows (WindowDict)
clear_dl_model (DLModelHandle)待续。。。。
本文出自勇哥的网站《少有人走的路》wwww.skcircle.com,转载请注明出处!讨论可扫码加群:


")
")
常用的6种方法")
 封装运动功能")






Qt Widgets Designer界面设计器和界面应用")
:if的bool判断, 变量的作用域范围, 格式字符串, 弹窗, 列表推导式, 一个点歌小程序")