少有人走的路
少有人走的路halcon的深度学习只做3件事,即“分类”,“对象检测”,“分割”。
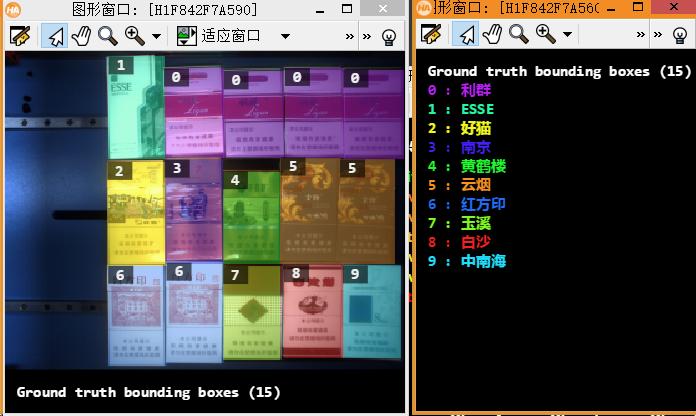
下面是“对象检测”的例子。
这个例子是检测香烟的品牌。
下图是训练完成后实际检测的效果。
训练时注意下面几个问题:
(一)图像宽高要求:
1.图像宽高需是64的整数倍;
2.最好在图像标注之前,就对图像缩放或裁剪至合适宽高;
3.如果已在不符合要求的图像上完成标注,那么需要把图像扩充至合适宽高;避免单纯对图像进行缩放或裁剪,导致图像与标注坐标不一致影响标注准确性;
(二)深度学习对gpu的要求
深度学习在训练阶段需要使用gpu,推理阶段可以使用cpu,需要加上下面的代码:
set_dl_model_param(DLModelHandle, 'runtime', 'cpu')
但是要注意的是:
目前勇哥发现一个问题,同一组图片,经gpu训练后,用gpu推理结果是正确的,但是如果改用cpu推理则结果不正确,有很大差别。
暂时还不知道为什么!
而且cpu推理速度极慢,在勇哥的10核20线程的机器上面(cpu占用100%),还不到6帧。在勇哥的工作笔记本i5 7600上面更惨,才0.3帧。
而在最差的古老显卡gtx 750ti上面,轻松跑到38帧。可见深度学习cpu计算根本就是一个虚头,计算速度和显卡比完全不在一个数量级上面。
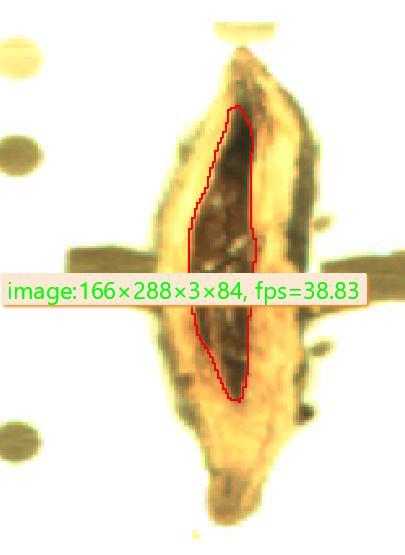
深度学习对gpu的计算能力要求极高,一块rtx2080ti显卡可以极大的提升计算能力。
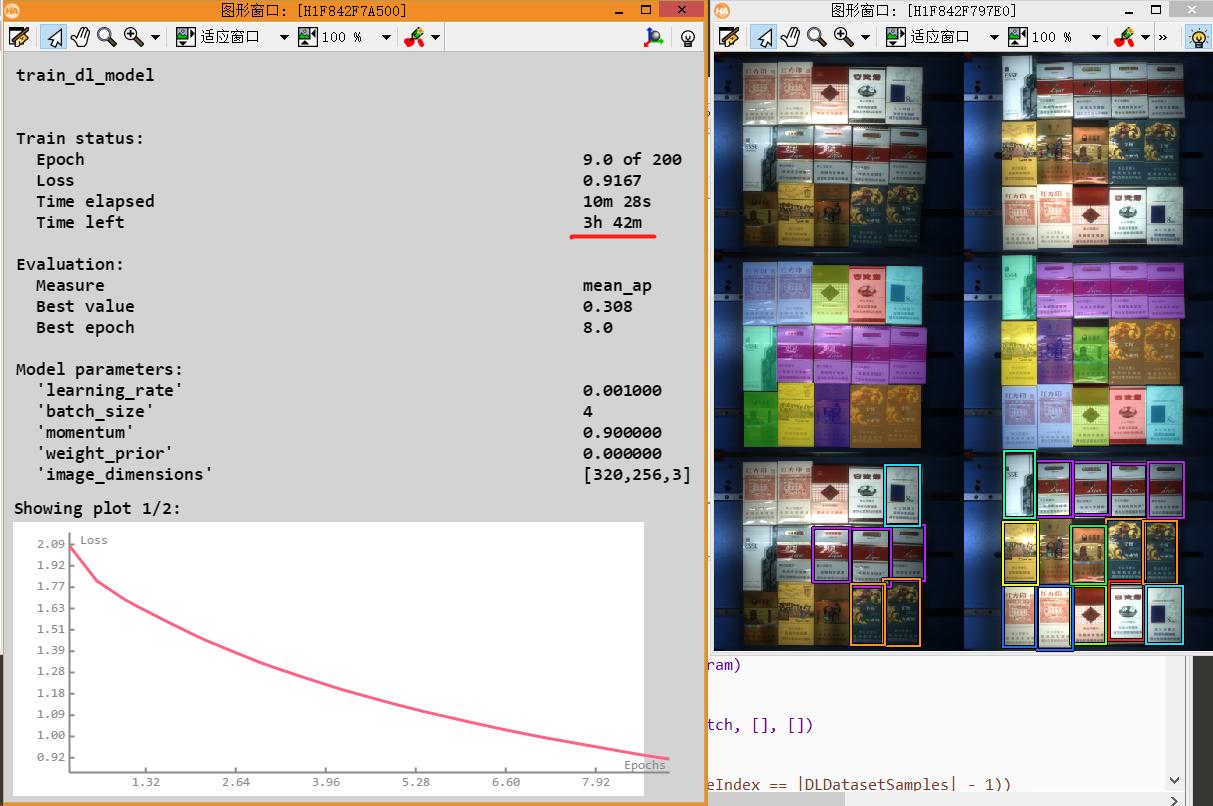
下图可以看到训练的过程看上去要接近4小时,但这个时间不准确。
实际在勇哥的破显卡gtx750ti上面,大约1小时训练完成。
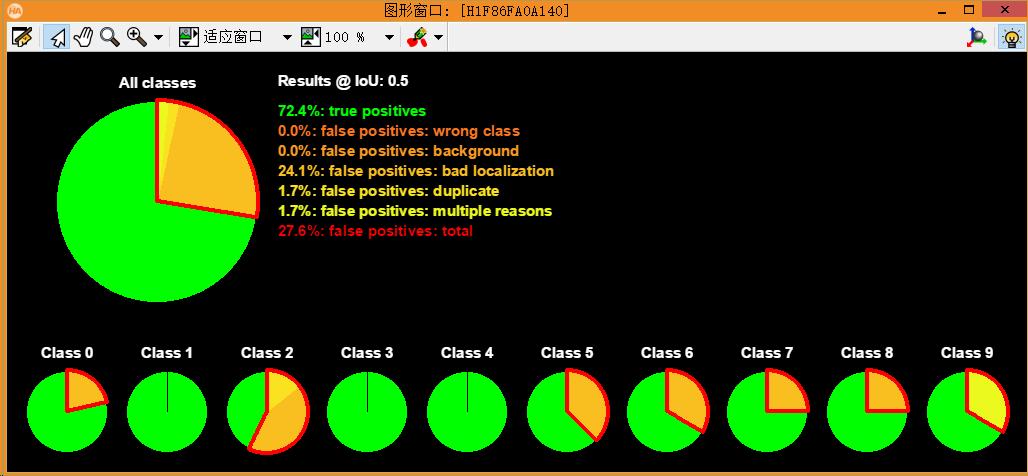
所有分类所占的比率。
Model := 'pretrained_dl_classifier_compact.hdl'
*Model := 'pretrained_dl_classifier_enhanced.hdl'
*Model := 'pretrained_dl_classifier_resnet50.hdl'
*Model := 'model_best.hdl'
AspectRatios := [0.5, 1, 2]
dev_update_off ()
dev_close_window ()
NumEpochs := 200
LearningRate := 0.001*1
read_dict('dataset.hdict',[], [], DLDataset)
get_dict_tuple (DLDataset, 'class_ids', ClassIDs)
get_dict_tuple (DLDataset, 'class_names', ClassNames)
list_image_files ('images', 'default', 'recursive', ImageFiles)
read_image (Image, ImageFiles[0])
get_image_size(Image, Width, Height)
Scale := 1
Width := (Width / Scale) / 64 * 64
Height := (Height / Scale) / 64 * 64
count_channels(Image, Channels)
if(Model == 'model_best.hdl')
read_dl_model('model_best.hdl', DLModelHandle)
else
create_dict (DLModelDetectionParam)
set_dict_tuple (DLModelDetectionParam, 'image_dimensions', [Width, Height, Channels])
set_dict_tuple (DLModelDetectionParam, 'min_level', 2)
set_dict_tuple (DLModelDetectionParam, 'max_level', 4)
set_dict_tuple (DLModelDetectionParam, 'num_subscales', 3)
set_dict_tuple (DLModelDetectionParam, 'aspect_ratios', AspectRatios)
*set_dict_tuple (DLModelDetectionParam, 'capacity', 'medium')
set_dict_tuple (DLModelDetectionParam, 'capacity', 'high')
get_dict_tuple (DLDataset, 'class_ids', ClassIDs)
set_dict_tuple (DLModelDetectionParam, 'class_ids', ClassIDs)
create_dl_model_detection (Model, |ClassIDs|, DLModelDetectionParam, DLModelHandle)
endif
split_dl_dataset (DLDataset, 70, 20, [])
create_dict (PreprocessSettings)
set_dict_tuple (PreprocessSettings, 'overwrite_files', true)
create_dl_preprocess_param_from_model (DLModelHandle, 'false', 'full_domain', [], [], [], DLPreprocessParam)
preprocess_dl_dataset (DLDataset, 'dataset', DLPreprocessParam, PreprocessSettings, DLDatasetFileName)
* Inspect several randomly selected preprocessed DLSamples visually.
create_dict (WindowDict)
get_dict_tuple (DLDataset, 'samples', DatasetSamples)
for Index := 0 to |DatasetSamples|-1 by 1
SampleIndex := round(rand(1) * (|DatasetSamples| - 1))
read_dl_samples (DLDataset, SampleIndex, DLSample)
dev_display_dl_data (DLSample, [], DLDataset, 'bbox_ground_truth', [], WindowDict)
endfor
*2.) TRAIN ***
tuple_min2(round(|DatasetSamples|*0.7), 64, BatchSize)
set_dl_model_param_max_gpu_batch_size (DLModelHandle, BatchSize)
set_dl_model_param (DLModelHandle, 'learning_rate', LearningRate)
set_dl_model_param (DLModelHandle, 'runtime_init', 'immediately')
create_dl_train_param (DLModelHandle, NumEpochs, 1, 'true', 42, [], [], TrainParam)
train_dl_model (DLDataset, DLModelHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos)
dev_close_window ()
dev_get_window(WindowHandle)
dump_window(WindowHandle, 'png', 'train')
*3.) EVALUATE ***
create_dict (GenParamEval)
set_dict_tuple (GenParamEval, 'detailed_evaluation', true)
set_dict_tuple (GenParamEval, 'show_progress', true)
evaluate_dl_model (DLDataset, DLModelHandle, 'split', 'test', GenParamEval, EvaluationResult, EvalParams)
create_dict (DisplayMode)
set_dict_tuple (DisplayMode, 'display_mode', ['pie_charts_precision','pie_charts_recall'])
dev_display_detection_detailed_evaluation (EvaluationResult, EvalParams, DisplayMode, WindowDict)
dev_get_window(WindowHandle)
dump_window(WindowHandle, 'png', 'recall')
dev_close_window ()
dev_get_window(WindowHandle)
dump_window(WindowHandle, 'png', 'precision')训练完成后,生成结果model_best.hdl,这个文件有137M。
未完待续。。。。
本文出自勇哥的网站《少有人走的路》wwww.skcircle.com,转载请注明出处!讨论可扫码加群:


")
")
常用的6种方法")
 封装运动功能")

:if的bool判断, 变量的作用域范围, 格式字符串, 弹窗, 列表推导式, 一个点歌小程序")
:与C#不同点,鸭子类型,多线程,多进程编程,访问控制,事件委托实现,lambda表达式,常用内置库,为啥说python简单易用?")
Qt Widgets Designer界面设计器和界面应用")
")